Baixando Dados de Bitcoin, Ethereum e Outras Criptomoedas com Python
Utilize a API da Coinbase para ter acesso aos dados atualizados das criptomoedas.
Queridas por muitos, odiadas por outros, as criptomoedas dividem opiniões. O que é inegável, no entanto, é que pela sua natureza mais recente e tecnológica, é consideravelmente mais simples acessar uma base de dados de criptomoedas do que é tipicamente com os ativos brasileiros.
No QuantBrasil nós já ensinamos a criar sua própria base de dados de ações e até a exportar valores atualizados do ProfitChart. Hoje nós continuaremos nossa saga à procura da base de dados perfeita e aprenderemos como acessar dados de preços de criptos.
Se tudo que você está atrás, porém, é baixar os preços para executar estratégias, nós já lhe poupamos esse trabalho. No Simulador de Estratégias do QuantBrasil você pode realizar backtests em várias criptomoedas, das mais famosas como Bitcoin e Ethereum, até as mais voláteis como Dogecoin.
No entanto, se você é partidário do Do It Yourself, sem problemas. Mãos à obra!
Escolhendo a API
Talvez a parte mais sensível desse projeto é escolher qual API utilizar. API, do inglês Application Programming Interface, é uma forma que corretoras e outros serviços disponibilizam para que você se comunique com eles. Existem diversas por aí:
Não é objetivo desse post fazer um apanhado sobre pontos fortes e fracos de cada uma delas e é capaz que todas (e outras não mencionadas) suportem o que pretendemos fazer hoje de forma simples. No entanto, a Coinbase lançou recentemente a Coinbase Cloud, com diversos serviços de suporte para produtos de cripto e decidi utilizá-la.
Note que a API da Coinbase possui endpoints que podem ser classificados como públicos ou privados. Os endpoints públicos são aqueles de conhecimento geral, por exemplo os dados históricos do Ethereum ou o book de negociações do Bitcoin. Já os privados contém dados relativos a um usuário específico: por exemplo, todos os seus trades executados no mês de Abril.
Como estamos interessados apenas em dados públicos, nosso código ficará ainda mais simples. Fosse o caso de querermos dados privados, precisaríamos de uma API key.
Vamos ao que interessa então e aprender a baixar os dados históricos de criptomoedas.
Baixando dados do Bitcoin
A API da Coinbase é bastante robusta e eu convido você a explorá-la. Para fins de dados históricos, porém, estamos interessados apenas na área de Exchange.
Existem duas formas de se acessar os dados: através de uma API REST ou utilizando websockets.
REST API vs WebSockets
Se você é mais familiarizado com desenvolvimento de software, já deve ter se deparado com esses termos anteriormente. Se não, não tem problema! Vamos explicar rapidamente a diferença entre esses dois protocolos de modo que você possa fazer a melhor decisão para o seu caso de uso.
Uma API REST é a forma mais tradicional de se comunicar com um serviço. Nela, o provedor expõe uma URL, também chamada de endpoint, onde o consumidor (ou cliente) faz uma requisição HTTP utilizando parâmetros previamente acordados (por exemplo, na documentação da API).
Tecnicamente falando, uma API REST deve seguir alguns princípios, como ser idempotente. Sem entrar em muitos detalhes técnicos, esse tipo de comunicação é tradicional no sentido que utiliza-se o padrão cliente - servidor. Ou seja, o cliente faz uma requisição para o servidor, espera uma resposta, e fecha a comunicação. Se dali a pouco o dado mudou (como é o caso com APIs de ativos financeiros), outra requisição tem que ser feita.
Já na abordagem via WebSockets o cliente abre uma conexão com o servidor, mas ela não necessariamente é fechada. Ou seja, abre-se uma espécie de "pipeline" de dados que são atualizados em tempo real sem que o cliente precise solicitar os dados mais recentes.
É como se você comparasse ter uma cascata de água natural na sua casa (WebSockets) versus ter que ir na cozinha apertar o botão do filtro (API REST).
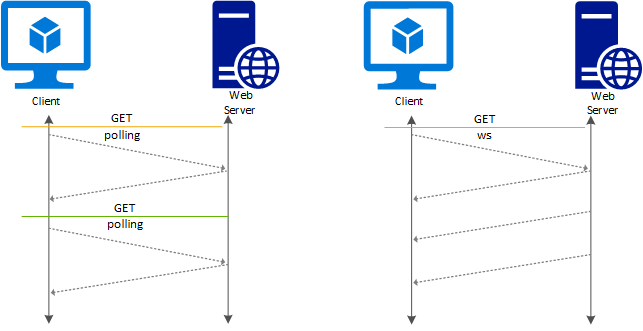
Qual é melhor? Como sempre na computação, depende do seu caso de uso. Você precisa de uma fonte de água natural na sua casa? Provavelmente não. A decisão entre API REST vs WebSockets depende de quão frequente você deseja que os dados sejam atualizados.
Por exemplo, se você quer o dado da última negociação do Bitcoin em real time, então WebSockets serão uma melhor solução. Por outro lado, se sua aplicação permite um delay de 15 minutos, então é mais que suficiente fazer uma requisição nesse período utilizando a API REST.
No nosso exemplo de hoje, não estamos tão preocupados em termos dados em real time, portanto utilizaremos a API REST.
Descobrindo o product id
Agora que decidimos qual serviço utilizaremos, podemos nos aprofundar na API da Coinbase.
De forma simplificada, todos os pares presentes na plataforma são chamados de produtos, e consequentemente possuem um product id. Esse id será utilizado para recuperar os dados históricos mais pra frente.
Existe um endpoint específico para retornar todos os trading pairs, e eu convido você a explorá-lo. Uma outra forma de vê-los é ir na página de Market Information da Coinbase e ver alguns dos pares mais famosos, além de outros detalhes.
Sendo assim, o product id do Bitcoin é BTC-USD, do Ethereum é ETH-USD, da Dogecoin é DOGE-USD, etc. Anote esse id sempre que quiser acessar a base de preços.
Baixando candles
Já falei demais: agora checou a hora de escrever algum código. Utilizaremos o endpoint de product candles para recuperar os dados de um par.
Antes, porém, precisamos descobrir quais são os parâmetros do endpoint, ou seja, quais dados precisamos enviar para a Coinbase para recuperar exatamente os dados que queremos.
Além do product id que já vimos, a API suporta os parâmetros start, end e granularity.
Os dois primeiros são óbvios: eles representam o intervalo que queremos buscar os dados.
Já a granularidade nada mais é do que o timeframe do dado. Uma granularity de 900 representa 900 segundos, ou 15 minutos (M15). Já 86400 equivaleria ao timeframe diário (D1).
Atente que nem todas as granularidades são suportadas. Por exemplo, o valor de 7200 (ou 120 minutos) não é aceito. Há uma saída, porém: no final desse tutorial nós aprenderemos a utilizar a função resample para gerar timeframes customizados.
A tabela a seguir representam as granularidades aceitas pela Coinbase no momento da escrita deste post:
| Granularidade | Período | Timeframe | ||
|---|---|---|---|---|
| 60 | 1 minuto | M1 | ||
| 300 | 5 minutos | M5 | ||
| 900 | 15 minutos | M15 | ||
| 3600 | 1 hora | H1 | ||
| 21600 | 6 horas | H6 | ||
| 86400 | 1 dia | D1 |
Importando as bibliotecas necessárias
Agora que já sabemos todos os parâmetros necesśarios, vamos realizar nosso primeiro teste e baixar os dados de preço diários do Bitcoin no 1º trimestre de 2022.
Para isso, vamos importar a biblioteca requests do Python e realizar a nossa primeira requisição HTTP.
import requests
# Mount URL
product_id = 'BTC-USD'
url = f"https://api.exchange.coinbase.com/products/{product_id}/candles"
# Define parameters
granularity = 86400
start_date = "2022-01-01T00:00:00"
end_date = "2022-03-31T23:59:59"
# Make sure to pass dates as ISO
params = {
"start": start_date,
"end": end_date,
"granularity": granularity
}
# Define request headers
headers = {"content-type": "application/json"}
data = requests.get(url, params=params, headers=headers)
data
Algumas coisas aconteceram aqui. Primeiro, construíamos a URL final que receberá nossa requisição (lembra dos endpoints?). Depois, ajustamos a granularidade para 86400 (ou seja, 1 dia de acordo com a nossa tabela) e definimos as datas como sendo o primeiro trimestre de 2022 no formato ISO 8601.
Importante: a API da Coinbase trabalha com datas em UTC, ou seja, 3 horas a mais que o horário de Brasília.
Fazemos uma requisição simples passando nossos parâmetros e definindo o content-type como JSON e recebemos um HTTP Status Code 200, ou seja, sucesso! Nossos dados foram baixados.
Ainda assim, esse não é o formato mais útil de todos. Em muitos casos, vamos querer analisar esses dados como um JSON ou, já que estamos no Python, como um DataFrame. Vamos então transformar os dados em JSON:
data = data.json()
data[:5][[1648684800, 45211, 47624.09, 47078.02, 45528.45, 17454.79144251], [1648598400, 46544.89, 47717.01, 47448.41, 47078.03, 12672.44584707], [1648512000, 46589, 48124.94, 47146.92, 47454.19, 15776.65108647], [1648425600, 46662.28, 48240, 46850.01, 47144.92, 18787.66318707], [1648339200, 44437.22, 46950, 44538.21, 46850.01, 10356.10317002]]Agora sim. Recebemos uma lista de listas (exibidas apenas as 5 primeiras), onde os dados obedecem a ordem: timestamp, low, high, open, close, volume. Note que a ordem é diferente do formato OHLCV que costumamos ver por aí!
Finalmente, vamos transformar nossa lista de listas em uma DataFrame respeitando a ordem dos elementos nas listas:
import pandas as pd
columns = ['timestamp', "low", "high", "open", "close", "volume"]
# Create a dataframe with results
df = pd.DataFrame(data=data, columns=columns)
# Create datetime column, set it as index and drop timestamp column
df['datetime'] = pd.to_datetime(df['timestamp'], unit='s')
df.set_index('datetime', inplace=True)
df.drop('timestamp', axis=1, inplace=True)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-03-31 | 45211.00 | 47624.09 | 47078.02 | 45528.45 | 17454.791443 |
| 2022-03-30 | 46544.89 | 47717.01 | 47448.41 | 47078.03 | 12672.445847 |
| 2022-03-29 | 46589.00 | 48124.94 | 47146.92 | 47454.19 | 15776.651086 |
| 2022-03-28 | 46662.28 | 48240.00 | 46850.01 | 47144.92 | 18787.663187 |
| 2022-03-27 | 44437.22 | 46950.00 | 44538.21 | 46850.01 | 10356.103170 |
| ... | ... | ... | ... | ... | ... |
| 2022-01-05 | 42500.00 | 47076.55 | 45817.13 | 43436.04 | 25067.674768 |
| 2022-01-04 | 45515.00 | 47532.89 | 46459.57 | 45814.61 | 16320.327129 |
| 2022-01-03 | 45700.00 | 47583.33 | 47299.06 | 46459.56 | 10841.810205 |
| 2022-01-02 | 46633.36 | 47990.00 | 47733.43 | 47299.07 | 6833.498455 |
| 2022-01-01 | 46205.00 | 47967.12 | 46211.24 | 47733.43 | 9463.661711 |
90 rows × 5 columns
E pronto! Repare que criamos uma nova coluna datetime onde trabalhamos com a data num formato mais amigável, transformando-a no índice no DataFrame. Por fim, como a coluna timestamp não nos será mais necessária, a deletamos.
Você já pode aproveitar o poder dos DataFrames com seus dados de cripto!
max_value = df['high'].max()
print(f"Max BTC price between {start_date[:10]} and {end_date[:10]} was ${max_value}")Max BTC price between 2022-01-01 and 2022-03-31 was $48240.0
Baixando dados de períodos maiores
Nosso código funcionou perfeitamente, mas ainda não terminamos nossa exploração. Para facilitar daqui pra frente, vamos encapsular o que fizemos até agora em uma função get_crypto_data:
def get_crypto_data(product_id, start_date, end_date, granularity):
# Mount URL
url = f"https://api.exchange.coinbase.com/products/{product_id}/candles"
# Make sure to pass dates as ISO
params = {
"start": start_date,
"end": end_date,
"granularity": granularity
}
# Define request headers
headers = {"content-type": "application/json"}
data = requests.get(url, params=params, headers=headers)
data = data.json()
columns = ['timestamp', "low", "high", "open", "close", "volume"]
# Create a dataframe with results
df = pd.DataFrame(data=data, columns=columns)
# Create datetime column, set it as index and drop timestamp column
df['datetime'] = pd.to_datetime(df['timestamp'], unit='s')
df.set_index('datetime', inplace=True)
df.drop('timestamp', axis=1, inplace=True)
return dfNossa função recebe todos os parâmetros necessários para baixar os dados. Sendo assim, vamos testá-la utilizando uma granularidade de 900, ou seja, 15 minutos:
df = get_crypto_data(
product_id="BTC-USD",
start_date="2022-01-01T00:00:00",
end_date="2022-03-31T23:59:59",
granularity=900
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime |
Ora, o DataFrame está vazio! Isso acontece pois a Coinbase limita a quantidade de data points retornados por requisição. Isso faz sentido, caso contrário algum usuário poderia solicitar todos os dados no timeframe de 1 minuto a cada segundo, fritando os servidores da empresa.
Segundo a documentação, o máximo de data points são 300 candles. Vamos reajustar nossos parâmetros de data para confirmar:
df = get_crypto_data(
product_id="BTC-USD",
start_date="2022-03-29T00:00:00",
end_date="2022-03-31T23:59:59",
granularity=900
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-03-31 23:45:00 | 45211.00 | 45586.97 | 45447.81 | 45528.45 | 331.390427 |
| 2022-03-31 23:30:00 | 45380.00 | 45746.51 | 45696.32 | 45447.30 | 167.929201 |
| 2022-03-31 23:15:00 | 45563.33 | 45715.25 | 45698.97 | 45696.32 | 164.113664 |
| 2022-03-31 23:00:00 | 45669.26 | 45819.98 | 45806.53 | 45700.78 | 102.271951 |
| 2022-03-31 22:45:00 | 45707.38 | 45845.09 | 45707.79 | 45809.89 | 71.263482 |
| ... | ... | ... | ... | ... | ... |
| 2022-03-29 01:00:00 | 47356.36 | 47470.99 | 47414.82 | 47445.39 | 73.969876 |
| 2022-03-29 00:45:00 | 47355.60 | 47630.71 | 47425.12 | 47411.67 | 154.791100 |
| 2022-03-29 00:30:00 | 47350.84 | 47445.43 | 47357.64 | 47425.08 | 93.277072 |
| 2022-03-29 00:15:00 | 47252.04 | 47519.09 | 47297.04 | 47357.62 | 205.391625 |
| 2022-03-29 00:00:00 | 47048.55 | 47356.05 | 47146.92 | 47297.04 | 315.522117 |
288 rows × 5 columns
Agora sim. Selecionando um período de 3 dias com a granularidade ajustada para 15 minutos, recuperamos 288 data points, praticamente no limite permitido por requisição.
Já andamos grande parte do caminho mas ainda não chegamos ao fim. 300 candles não fazem um verão, e portanto precisamos de um jeito de buscar quantos dados forem necessários, independente da limitação.
Vejamos o que a documentação nos sugere:
If you wish to retrieve fine granularity data over a larger time range, you will need to make multiple requests with new start/end ranges.
Trocando em miúdos: para recuperar mais dados que o limite precisamos iterar sobre o intervalo desejado e "quebrá-lo" em pedaços de 300 em 300 candles. Vamos resolver esse problema.
Iterando sobre o intervalo de tempo
Vamos retomar nosso intervalo original: o 1º trimestre de 2022. Conseguimos baixar os dados no timeframe diário, uma vez que existem menos de 300 pontos nessas configurações. Mas não fomos capazes de receber os dados no timeframe de 15 minutos por termos estourado o limite de 300 data points por requisição.
Para bypassar essa regra, criaremos o seguinte algoritmo:
- Inicializamos no início do intervalo;
- Incrementamos o intervalo com o número máximo de candles permitidos para a granularidade em questão;
- Baixamos os dados nesse subintervalo;
- Se o final do subintervalo for menor que o final do intervalo original, repetimos o passo 1;
- Ao final do loop, concatenamos os dados baixados em cada iteração.
Por exemplo, se o início do intervalo é 2022-01-01T00:00:00 (ou seja, meia noite do dia 01/01/2022 em UTC) e granularidade é 900 (ou seja, 15 minutos), sabemos que temos 4 blocos de 15 minutos por hora e 24 horas, sendo assim 96 candles de 15 minutos em um dia.
Em 3 dias, temos 288 candles (não é coincidência que nosso dataframe anterior tenha exatamente esse número de linhas).
Como sobram ainda 12 candles para o limite de 300, e cada candle tem 15 minutos, então ainda podemos "andar" mais 180 minutos (ou 3 horas). Sendo assim, poderíamos escrever:
df = get_crypto_data(
product_id="BTC-USD",
start_date="2022-01-01T00:00:00",
end_date="2022-01-04T03:00:00",
granularity=900
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-01-04 03:00:00 | 46023.08 | 46144.92 | 46102.58 | 46041.94 | 94.959678 |
| 2022-01-04 02:45:00 | 46088.57 | 46238.24 | 46201.38 | 46104.69 | 97.587071 |
| 2022-01-04 02:30:00 | 46077.15 | 46263.46 | 46130.41 | 46201.38 | 91.763870 |
| 2022-01-04 02:15:00 | 45950.00 | 46155.20 | 45984.17 | 46132.18 | 85.814546 |
| 2022-01-04 02:00:00 | 45951.46 | 46149.43 | 46060.37 | 45985.43 | 132.597476 |
| ... | ... | ... | ... | ... | ... |
| 2022-01-01 01:15:00 | 46736.81 | 46931.00 | 46762.51 | 46800.00 | 231.691797 |
| 2022-01-01 01:00:00 | 46573.65 | 46762.51 | 46656.85 | 46760.66 | 133.183740 |
| 2022-01-01 00:45:00 | 46566.17 | 46744.99 | 46603.71 | 46656.85 | 165.301353 |
| 2022-01-01 00:30:00 | 46334.08 | 46664.91 | 46359.10 | 46603.64 | 151.375780 |
| 2022-01-01 00:15:00 | 46211.35 | 46394.44 | 46315.46 | 46359.09 | 188.236630 |
300 rows × 5 columns
Embora o DataFrame tenha exatos 300 pontos, note que estamos "deslocados" de 1 ponto, uma vez que a contagem está começando em 00:15, e não às 00:00 como seria esperado. Podemos corrigir subtraindo 1 segundo das nossas datas inicial e final:
df = get_crypto_data(
product_id="BTC-USD",
start_date="2021-12-31T23:59:59",
end_date="2022-01-04T02:59:59",
granularity=900
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-01-04 02:45:00 | 46088.57 | 46238.24 | 46201.38 | 46104.69 | 97.587071 |
| 2022-01-04 02:30:00 | 46077.15 | 46263.46 | 46130.41 | 46201.38 | 91.763870 |
| 2022-01-04 02:15:00 | 45950.00 | 46155.20 | 45984.17 | 46132.18 | 85.814546 |
| 2022-01-04 02:00:00 | 45951.46 | 46149.43 | 46060.37 | 45985.43 | 132.597476 |
| 2022-01-04 01:45:00 | 46044.31 | 46205.05 | 46132.80 | 46060.38 | 98.783973 |
| ... | ... | ... | ... | ... | ... |
| 2022-01-01 01:00:00 | 46573.65 | 46762.51 | 46656.85 | 46760.66 | 133.183740 |
| 2022-01-01 00:45:00 | 46566.17 | 46744.99 | 46603.71 | 46656.85 | 165.301353 |
| 2022-01-01 00:30:00 | 46334.08 | 46664.91 | 46359.10 | 46603.64 | 151.375780 |
| 2022-01-01 00:15:00 | 46211.35 | 46394.44 | 46315.46 | 46359.09 | 188.236630 |
| 2022-01-01 00:00:00 | 46205.00 | 46500.00 | 46211.24 | 46316.17 | 317.402547 |
300 rows × 5 columns
Agora sim! Nossa requisição retorna exatamente os 300 primeiros data points de 2022 no timeframe de 15 minutos.
Como cada intervalo comporta 3 dias e 3 horas de dados, podemos utilizar o final do subintervalo como início do próximo, e "andar" mais 3 dias e 3 horas no final do subintervalo:
df = get_crypto_data(
product_id="BTC-USD",
start_date="2022-01-04T02:59:59",
end_date="2022-01-07T05:59:59",
granularity=900
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-01-07 05:45:00 | 41615.81 | 41850.00 | 41711.20 | 41834.30 | 290.354053 |
| 2022-01-07 05:30:00 | 41642.21 | 41945.65 | 41791.36 | 41712.43 | 459.702018 |
| 2022-01-07 05:15:00 | 41704.82 | 41893.85 | 41713.97 | 41788.88 | 284.561626 |
| 2022-01-07 05:00:00 | 41522.31 | 41746.54 | 41691.63 | 41718.69 | 282.162749 |
| 2022-01-07 04:45:00 | 41404.00 | 41772.31 | 41416.31 | 41689.99 | 575.720724 |
| ... | ... | ... | ... | ... | ... |
| 2022-01-04 04:00:00 | 46181.09 | 46398.41 | 46319.99 | 46248.78 | 85.736188 |
| 2022-01-04 03:45:00 | 46300.00 | 46385.20 | 46342.60 | 46319.84 | 88.525080 |
| 2022-01-04 03:30:00 | 46180.23 | 46342.60 | 46192.33 | 46342.60 | 98.737794 |
| 2022-01-04 03:15:00 | 46015.89 | 46211.75 | 46041.85 | 46192.33 | 106.962232 |
| 2022-01-04 03:00:00 | 46023.08 | 46144.92 | 46102.58 | 46041.94 | 94.959678 |
300 rows × 5 columns
E aí está. Recomeçamos exatamente de onde paramos e andamos os 300 candles permitidos.
Agora que você já entendeu o algoritmo podemos alterar get_crypto_data para fazer isso automaticamente:
from datetime import datetime, timedelta
def get_crypto_data(product_id, start_date, end_date, granularity):
# Mount URL
url = f"https://api.exchange.coinbase.com/products/{product_id}/candles"
# Delta is the increment in time from one candle to another
delta = timedelta(seconds=granularity)
# Coinbase's limitation
max_candles = 300
# Start from the last second of last day to prevent duplications
current_date = datetime.strptime(start_date, '%Y-%m-%dT%H:%M:%S') - timedelta(seconds=1)
end_date = datetime.strptime(end_date, '%Y-%m-%dT%H:%M:%S') - timedelta(seconds=1)
# We'll add results in each iteration to this list
results = []
# Iterate over interval
while current_date < end_date:
# Get next date. It's the current date + increment if still within the interval,
# else it's the end date
next_date = current_date + max_candles * delta
next_date = next_date if next_date < end_date else end_date
# Make sure to pass dates as ISO
params = {
"start": current_date.isoformat(),
"end": next_date.isoformat(),
"granularity": granularity
}
headers = {"content-type": "application/json"}
data = requests.get(url, params=params, headers=headers)
data = data.json()
# Make sure to add more recent data to the top of the list
results = data + results
# Update cursor
current_date = next_date
columns = ['timestamp', "low", "high", "open", "close", "volume"]
# Create a dataframe with results
df = pd.DataFrame(data=results, columns=columns)
# Create datetime column, set it as index and drop timestamp column
df['datetime'] = pd.to_datetime(df['timestamp'], unit='s')
df.set_index('datetime', inplace=True)
df.drop('timestamp', axis=1, inplace=True)
return dfAlgumas coisas importantes aqui:
- Utilizamos a função
timedeltapara manipular a data, subtraindo 1 segundo dos intervalos; - Definimos
max_candlescomo o limite de data points em cada iteração; - Definimos
next_datecomo o final do subintervalo; - Baixamos os dados e os adicionamos a uma lista;
- No final, convertermos a lista para DataFrame.
Chegou a hora de testar nossa intenção original: baixar todos os candles de 15 minutos do Bitcoin no 1º trimestre de 2022.
df = get_crypto_data(
product_id="BTC-USD",
start_date="2022-01-01T00:00:00",
end_date="2022-03-31T23:59:59",
granularity=900
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-03-31 23:45:00 | 45211.00 | 45586.97 | 45447.81 | 45528.45 | 331.390427 |
| 2022-03-31 23:30:00 | 45380.00 | 45746.51 | 45696.32 | 45447.30 | 167.929201 |
| 2022-03-31 23:15:00 | 45563.33 | 45715.25 | 45698.97 | 45696.32 | 164.113664 |
| 2022-03-31 23:00:00 | 45669.26 | 45819.98 | 45806.53 | 45700.78 | 102.271951 |
| 2022-03-31 22:45:00 | 45707.38 | 45845.09 | 45707.79 | 45809.89 | 71.263482 |
| ... | ... | ... | ... | ... | ... |
| 2022-01-01 01:00:00 | 46573.65 | 46762.51 | 46656.85 | 46760.66 | 133.183740 |
| 2022-01-01 00:45:00 | 46566.17 | 46744.99 | 46603.71 | 46656.85 | 165.301353 |
| 2022-01-01 00:30:00 | 46334.08 | 46664.91 | 46359.10 | 46603.64 | 151.375780 |
| 2022-01-01 00:15:00 | 46211.35 | 46394.44 | 46315.46 | 46359.09 | 188.236630 |
| 2022-01-01 00:00:00 | 46205.00 | 46500.00 | 46211.24 | 46316.17 | 317.402547 |
8640 rows × 5 columns
E aí está. Nos 90 dias do 1º trimestre existem 90 * 96 = 8640 candles, justamente o tamanho do nosso DataFrame. Vitória!
Baixando dados em outros timeframes
Nossa última missão do dia é descobrir como fazer para utilizar granularidades customizadas. Ora, pode ser que o seu timeframe favorito não esteja na lista!
Felizmente existe a poderosíssima função resample no pandas. Suponhamos que nosso objetivo é baixar todos os dados de Ethereum no 1º trimestre de 2022, porém no timeframe de 120 minutos.
No entanto, a granularidade suportada mais próxima disso é 3600, ou 1 hora. Vamos começar então baixando os dados no timeframe de granularidade mais próxima:
df = get_crypto_data(
product_id="ETH-USD",
start_date="2022-01-01T00:00:00",
end_date="2022-03-31T23:59:59",
granularity=3600
)
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-03-31 23:00:00 | 3263.42 | 3298.72 | 3291.51 | 3283.08 | 5846.861734 |
| 2022-03-31 22:00:00 | 3274.34 | 3294.20 | 3288.29 | 3291.30 | 5073.242391 |
| 2022-03-31 21:00:00 | 3288.10 | 3307.39 | 3300.57 | 3288.27 | 6042.383361 |
| 2022-03-31 20:00:00 | 3280.00 | 3305.00 | 3284.27 | 3300.58 | 9915.034122 |
| 2022-03-31 19:00:00 | 3283.32 | 3312.90 | 3309.73 | 3284.17 | 11106.793949 |
| ... | ... | ... | ... | ... | ... |
| 2022-01-01 04:00:00 | 3705.09 | 3727.34 | 3723.01 | 3706.87 | 6879.855088 |
| 2022-01-01 03:00:00 | 3721.99 | 3736.08 | 3728.01 | 3722.96 | 3711.649049 |
| 2022-01-01 02:00:00 | 3722.01 | 3737.38 | 3724.81 | 3727.94 | 5135.417450 |
| 2022-01-01 01:00:00 | 3709.15 | 3748.11 | 3722.79 | 3724.22 | 9223.416393 |
| 2022-01-01 00:00:00 | 3675.44 | 3728.87 | 3675.81 | 3722.78 | 8114.958722 |
2160 rows × 5 columns
Nossa função retornou os dados corretamente, porém precisamos agrupá-los de forma que se encaixe no nosso timeframe. Como queremos combiná-los em intervalos de 2 horas, precisamos agregar cada 2 linhas em uma nova, utilizando as seguintes regras:
- Queremos o menor valor na coluna low;
- Queremos o maior valor na coluna high;
- Queremos o primeiro valor na coluna open;
- Queremos o último valor na coluna close;
- Queremos a soma dos valores na coluna volume.
Por exemplo, os dois primeiros candles do DataFrame (2022-01-01 00:00:00 e 2022-01-01 01:00:00) devem ser agregados em um candle cujo datetime é 2022-01-01 00:00:00, low seja 3675.44, high seja 3748.11, open seja 3675.81, close seja 3724.22 e _volume seja 17338.36.
df = df.resample('120 min').agg({
"low": "min",
"high": "max",
"open": "first",
"close": "last",
"volume": "sum"
})
df
| low | high | open | close | volume | |
|---|---|---|---|---|---|
| datetime | |||||
| 2022-01-01 00:00:00 | 3675.44 | 3748.11 | 3675.81 | 3724.22 | 17338.375115 |
| 2022-01-01 02:00:00 | 3721.99 | 3737.38 | 3724.81 | 3722.96 | 8847.066499 |
| 2022-01-01 04:00:00 | 3702.43 | 3763.83 | 3723.01 | 3735.00 | 12822.868144 |
| 2022-01-01 06:00:00 | 3700.00 | 3742.87 | 3735.01 | 3714.27 | 13458.744710 |
| 2022-01-01 08:00:00 | 3708.25 | 3733.47 | 3714.88 | 3718.44 | 3064.374500 |
| ... | ... | ... | ... | ... | ... |
| 2022-03-31 14:00:00 | 3336.36 | 3389.15 | 3381.40 | 3351.14 | 26798.403425 |
| 2022-03-31 16:00:00 | 3265.53 | 3354.96 | 3350.97 | 3296.00 | 38338.470086 |
| 2022-03-31 18:00:00 | 3260.99 | 3312.90 | 3295.71 | 3284.17 | 23085.379080 |
| 2022-03-31 20:00:00 | 3280.00 | 3307.39 | 3284.27 | 3288.27 | 15957.417484 |
| 2022-03-31 22:00:00 | 3263.42 | 3298.72 | 3288.29 | 3283.08 | 10920.104125 |
1080 rows × 5 columns
Aposto que você não acreditava que seria tão simples. Sim, passando a string '120 min' o pandas é esperto o suficiente para reagrupar as linhas utilizando as funções específicas para cada coluna. Note como o novo DataFrame é metade do original. Elegante.
Conclusão
Graças à natureza tecnológica das criptomoedas existem diversas APIs públicas com seus dados históricos. A Coinbase, uma das maiores exchanges americanas e que é listada na NASDAQ, disponibiliza sua API através da Coinbase Cloud.
Aprendemos que a Coinbase limita em 300 dados por requisição. Sendo assim, devemos fazer múltiplas requisições iterativamente se queremos baixar mais dados que isso.
Por fim, nem todos os timeframes são aceitos. Apenas certas granularidades são permitidas, como M15, H1 e D1. No entanto, utilizando o poderoso resample podemos agregar candles de acordo com regras específicas.
Se você tem interesse em estratégias quantitativas para criptomoedas, considere criar sua conta no QuantBrasil. No QuantBrasil oferecemos o Simulador de Estratégias, onde você pode realizar backtests em criptomoedas e outros ativos de forma simples e rápida.
Sendo membro Premium você desbloqueia todas as estratégias, ativos e timeframes no nosso simulador, além de outras ferramentas imprescindíveis para investidores e traders. Confira nossos planos!
Até a próxima!